
Adaptive and generative media experiences
Published by Cinematronic ApS © 2023
Introduction
In 2023, we conducted several new projects and tests as part of our ongoing quest to create new technologies for enhancing user experiences through User Insights and Adaptive Content in various forms. One project explored ways to implement adaptive media using generative text-to-image models. With assistance from two student groups attending IT & Design at Aalborg University, we tested two types of media adaptations which would not require specialised biosensor equipment. One approach was generating a simple User Preference profile based on users' ranking of potentially emotionally activating images (depicting spider snakes, etc.), then displaying content with the highest probability of creating emotional impact. The other approach was to make adaptations via Emotion Recognition through facial expressions captured with a webcam.
For both cases, we used the classic tale of Little Red Riding Hood for content and transformed it into an interactive media experience. In this version, a young girl journeys through a forest to visit her grandmother and encounters a wolf. The wolf tricks her into a detour. While she is preoccupied, the wolf devours the grandmother and assumes her identity. Upon arrival at the grandmother's house, the girl becomes wary of the wolf's disguise. Our adaptation focuses only on these key characters and their interactions in the forest, making story variations by generative images possible. The storytelling process was simplified by dividing the script into distinct scenes, which could be activated by using an adaptive media player.

Figure 1: The concept of a video player (A) with text-to-speech (B) and a track selector (C) like Cinematronic Adaptive Media Player.
Methodology & Technology
Advancements in generative text-to-image models support Cinematronic's goals of creating innovative forms of personalised and adaptive media. We explore techniques by applying them to a generative retelling, where we focus on two adaptations: 1) dynamically adjusting the visuals based on a facial expression-to-emotion model and 2) tailoring the story based on viewers' fears. In both cases, the goal is to intensify the emotional impact of the viewer. We conducted a study involving 97 respondents to evaluate these adaptations, comparing adaptive and baseline versions. The result is a dramatic change in the viewing experience based on the genre preferences of the respondents.
The AI-generated content was structured around three core scenes with narrative and character descriptions. These scenes encompassed:
-
A single visual style and a neutral tone characterise a baseline version.
-
A dynamic version built upon the baseline by introducing "scary" and "very scary" variations.
-
A personalised version was crafted to align with a specific fear chosen by the viewers, which included snakes, spiders, gore, drowning, and heights. This adaptation included additional interludes and endings tailored to the individual fears selected by the viewer.
Depending on the chosen version, viewers were presented with a sequence of generated clips corresponding to the selected adaptation. However, in contrast to the static nature of the baseline and personalised versions, the dynamic version adjusted the sequence of clips shown during viewing based on real-time feedback or predetermined criteria.

Figure 2: Depiction of personalised clip distribution to be activated throughout the viewing experience.
We used ElevenLabs Prime Voice AI text-to-speech software for narration and incorporated ambient sounds and effects into the clips. These included growls for the wolf and rustling bushes. The audio elements were mixed with the narration to create a seamless experience. For visuals, we employed Stable Diffusion for image generation. While not category-specific, the model has undergone comprehensive training across various styles and images, ensuring reliable results.
The AUTOMATIC1111 web-based user interface (version 1.2) was used to operate Stable Diffusion, leveraging its text-to-image and image-to-image functionalities. We employed positive and negative prompts for text-to-image, while image-to-image included an input image for further guidance. The Deforum extension was used for video, enabling interpolation between keyframes through repeated image-to-image processes. Additionally, ControlNet was used to refine movement control in specific scenes, incorporating techniques like skeletal animations, depth images and facial expressions.
Multiple techniques were used to enhance the quality of the generated images, employing different prompt designs to guide the model towards the desired outputs. In our study, the dynamic condition adjusts the scariness level experienced by viewers, providing a tailored experience. We introduced three levels of scariness: neutral, scary, and very scary. The scarier versions of clips are generated by adjusting prompts from the baseline while maintaining narrative coherence. Terms like 'aggressive' and 'evil' were added to the positive prompt, while terms like 'colourful' and 'life' were included in the negative prompt to counteract this effect.
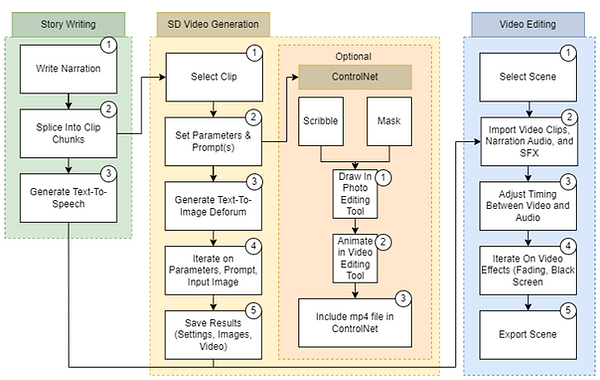
Figure 3: Illustration of the video generation workflow, from narration to scene export.
Users' emotional experiences
We dynamically adjust the scariness levels from clip to clip, determining the appropriate level based on the viewer's response to the previous clip. If fear is detected in the viewer during the current clip, we may decrease the scariness level for the next clip. Conversely, if no fear is detected, we may increase the scariness. Our adaptation relies solely on discrete emotion labels, particularly the presence of 'fear' during the current clip, rather than continuous fear measurements. Emotion detection captures the prevailing emotion throughout each clip. The illustration below shows how AI-generated images can support different types of fear based on the same source material.

Figure 4: Different AI-generated images were produced to support different types of fear.
Our personalised storytelling approach tailored the narrative to address each viewer's fears. Using generative models, we could make a wide range of adaptations. Our focus was primarily on enhancing the scariness of the narrative for individual viewers. We personalised the story according to viewers' specific phobias, selecting from five common fears: arachnophobia (fear of spiders), ophidiophobia (fear of snakes), hemophobia (fear of blood and injuries), acrophobia (fear of heights), and thalassophobia (fear of deep water). These fears were chosen for their prevalence and
Compatibility with the Little Red Riding Hood narrative. Personalised content is inserted into three key moments of the story: when Little Red Riding Hood picks a flower, encounters her fears on the wrong path, and the story's conclusion. The viewer's indication of a stronger fear of heights or deep water determines the ending.
Participants viewed predetermined content for the baseline and personalised conditions, while the dynamic condition utilised a video streaming setup. This involved generating an MPEG-DASH stream on a server and dynamically splicing clips to offer a smooth viewing experience through a web application. Emotion detection was integrated into the viewing app, streaming webcam images to a server for analysis. Using OpenCV's HAAR cascade classifier, faces were detected, cropped, resized, and processed through a custom emotion recognition model based on the Xception architecture. This model, trained on the FER2013 dataset, achieved an overall accuracy of 75% on test data, with varied accuracies for different emotions. Emotion labels were cached during each clip on the client side and used to determine if a viewer was "fearful" based on a threshold of 10% of frames labelled as such. Requests for the next clip were sent four seconds before the current one ended to ensure a seamless transition.


Figure 5: (LEFT) Illustration of user data process, including assessing individual fear parameters. (RIGHT) Screenshot from the fear evaluation tool used before streaming content to the viewers.
Participants in the personalised condition rated their fear levels for various categories (spiders, snakes, gore, heights, deep water) on a five-point scale (Low–High). Four representative images accompanied each fear category, and participants were asked to indicate how uncomfortable these images made them feel. Based on their responses, the type of personalisation experienced by participants was determined. Clips were selected based on their highest-ranked fears among those used for interludes (spiders, snakes, or gore) and endings (heights or deep water).
The distribution among the six personalised variants was not uniform, with 13 respondents expressing the highest fear of spiders and heights, followed by spiders and drowning (7), gore and drowning (4), gore and heights (3), snakes and drowning (3), and snakes and heights (1). After viewing the video for their assigned conditions, respondents answered 11 questions about their viewing experience. They also could leave comments on the form and during post-experience conversations.
Results
11 sets of results from the User Preference test are shown in Figure 6 (paired two and two). The top lines of each pair represent answers from respondents who have seen a non-personalised version of Litte Red Riding Hood. In contrast, the bottom lines (of the pairs) represent respondents exposed to a personalised version. to add your own text and edit me. It's easy.

Figure 6: Results from user-reported experiences of the User Preference test, based on individualised adaptive content (bottom line) and generic baseline content (top line).
Upon initial examination of the data from figure 6, the experiences appear to share some common features. However, certain notable exceptions stand out, particularly in “excitement”, “pleasantness”, “curiosity”, and “boredom”. The personalised version is significantly more exciting, with 61.3% of respondents agreeing or strongly agreeing, compared to the baseline's 32.2%. A similar trend is observed for curiosity, with most respondents indicating curiosity during the viewing.
Like the User Preference test, we reach similar results from the Emotion Recognition tests, as illustrated in Figure 7, where respondents generally reported higher experience scores when comparing personalised (bottom lines) and non-personalised (top lines) stimuli exposures.
Conclusion
In conclusion, our study showcases the potential of AI-generated media to cater to individual preferences and deliver enriched storytelling experiences. Our initial test results indicate a potential for optimising user experiences using different types of media adaptations, and we gained considerable changes in UX results, even from smaller adaptive changes.
The dynamic adaptation across three scariness levels and real-time camera-based emotion recognition presents an innovative method for tailoring storytelling experiences based on viewer reactions. Likewise, the personalised adaptation, driven by individual fears identified through viewer profiles, provides a distinct level of customisation that aligns the narrative with viewer preferences and emotional responses.
These results also give indications of Cinematronic’s Interactive Adaptive Media System's expected potential. Upon completion, it will be able to cater to the individual needs of users in real time.